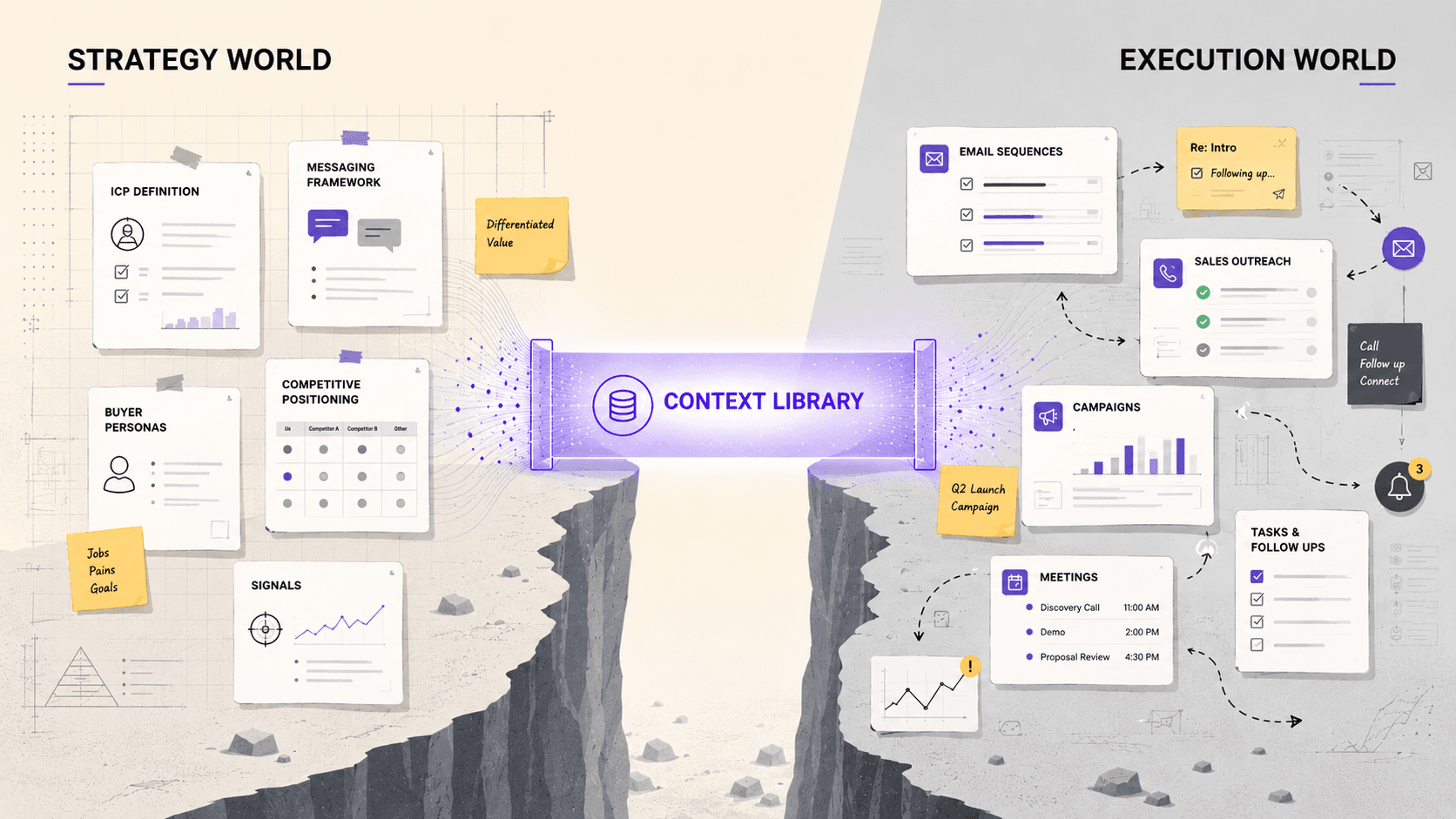
Hivekind vs. Data Tools
Data platforms made outbound scalable by solving discovery. ZoomInfo, Apollo.io, Cognism, and Seamless.ai became core to GTM stacks because they made contacts, ICPs, and intent visible. For years, that was enough.
Reviews across G2 shows that this constraint has now shifted. Users still acknowledge the value of data platforms, but they increasingly point out a different bottleneck: data tools show intent, but they do not convert it into conversations. Signals accumulate. Reps need to intervene. That gap is where the pipeline is lost. .
Reps see the signal, but they still need to interpret it, decide if it matters, find the right buyer group, verify contact data, write messaging, build a sequence, and send it. The gap between signal and conversation remains manual and slow.
Instead of failing at discovery, outbound now fails at pre-pipeline decisions like who to target, when to reach out and what to say to different buyers.
What Data Tools Are Designed To Do
Data tools are built on three assumptions:
- Data is inventory: static contacts, refreshed periodically
- Enrichment is snapshot-basis: titles, seniority, departments; little context.
- Personalization is superficial: sequences that rely on template-based variables and not real-time replies, context, changes and signals etc.
These assumptions made sense when outbound was volume-driven and templating worked, but they now impose structural limitations.
Core Limitations Identified Through G2 Feedback
G2 reviews surface four recurring gaps in the data category: independent of vendor:
A. Real-Time Intent Execution Gap
Intent is delivered as dashboards, reports, and batch alerts. Reps must then find contacts, verify accuracy, research context, draft messaging, and build sequences. There is no automated bridge that triggers a customized action the moment a signal is detected.
B. The Personalization Paradox
Variable-level personalization (“{{first_name}}”, “{{company_name}}”) is increasingly ineffective. Buyers recognize automation instantly. What’s missing is narrative derived from context: product launches, funding rounds, compliance events, hiring patterns, financial disclosures, PR, or digital footprint activity.
C. Data Past its Shelf Life
Static databases decay. G2 reviewers repeatedly mention credits wasted on bounces, stale titles, and outdated contacts. Data verification happens pre-purchase, not at the moment of send, leading to avoidable deliverability issues and waste.
No data verification layer is added to current tools and 10-20% of the data becomes stale per quarter.
D. Manual Workflows
Data tools require operators. SDRs and AEs orchestrate the workflow end-to-end via manual tasks: enrichment to research to drafting to sequencing to sending. They increasingly want systems that execute on goals, not dashboards that require labor.
These complaints are operational. They define the frontier the category never crossed.

Current manual steps in the workflow
- buyer group identification
- contextual interpretation of signals
- narrative generation
- sequencing across roles and channels
- timing
- verification
- Deliverability checks
- adaptation based on responses
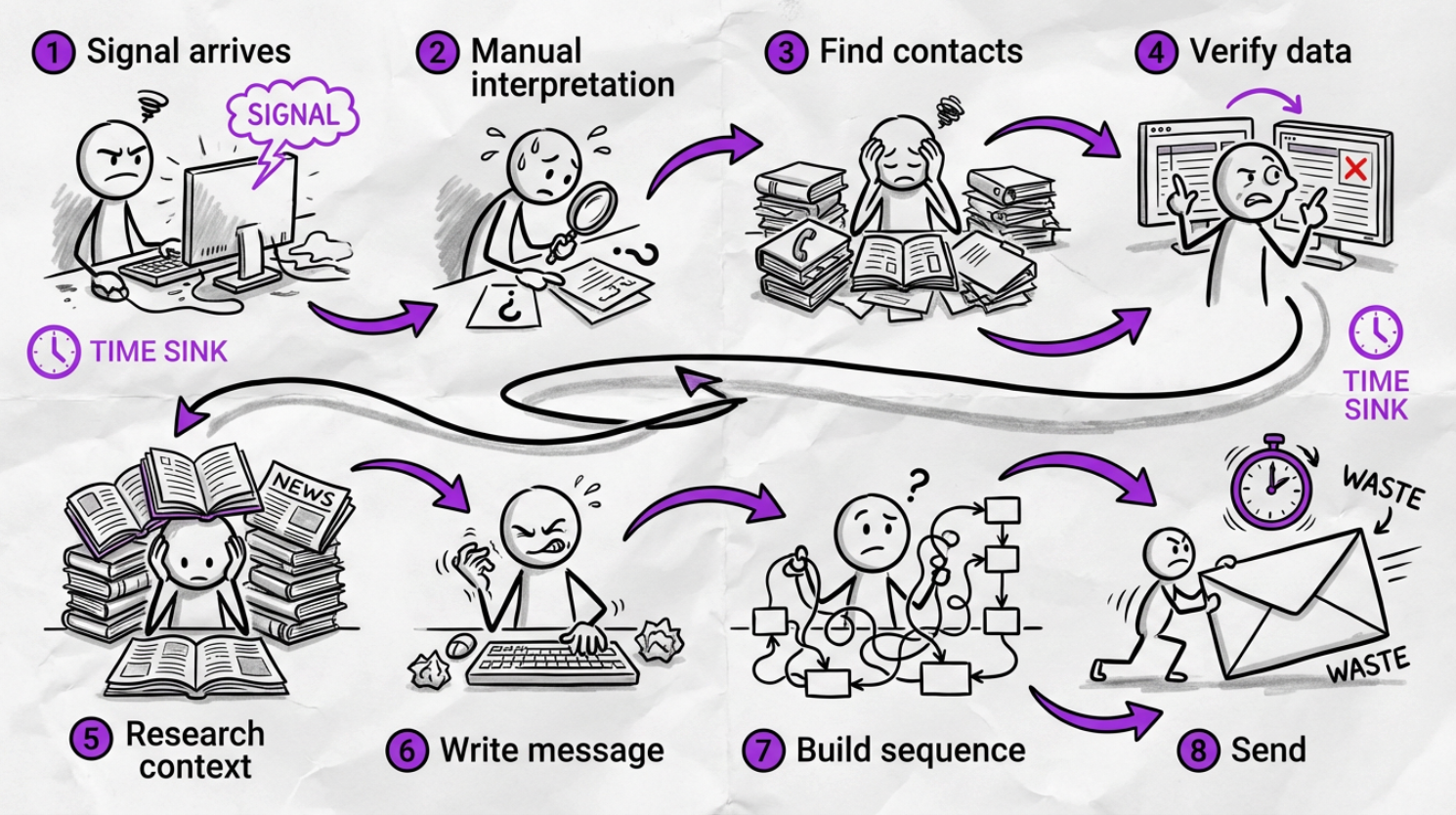
This is where the workload sits today, and with huge latency gaps.
Most enterprise teams describe this gap consistently: “We have intent; we can’t action it fast enough.” That sentence appears across many G2 vendor pages in some form. The message is clear: intent that cannot be acted on becomes noise and then leads to people marking you as SPAM.
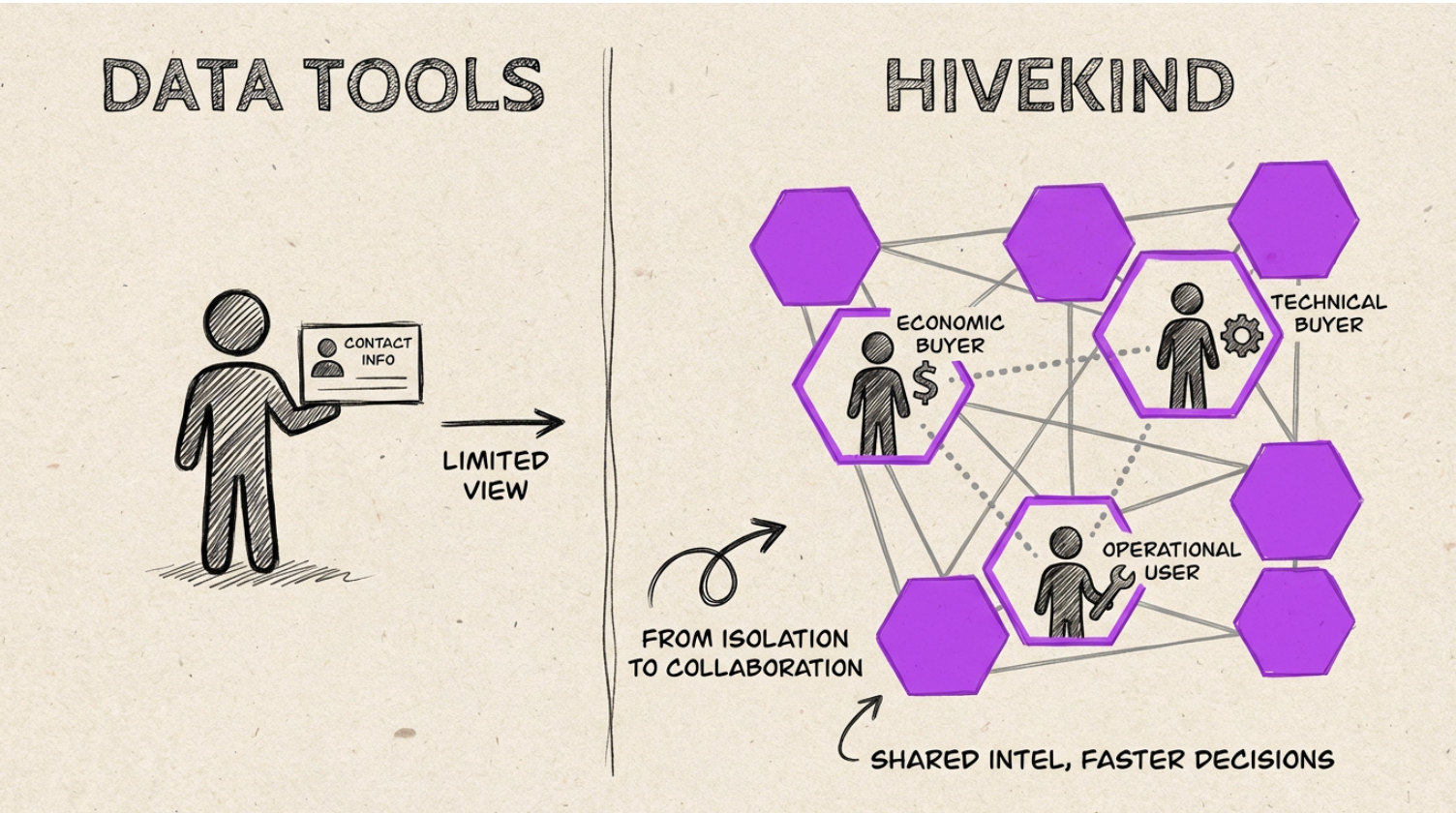
Buyer Groups vs Individuals
Data tools expose individuals. Enterprise deals involve groups. Reps manually reconstruct the buying committee and align messaging across roles.
Hivekind treats the buyer group as the default unit of activation, not the individual. Signals are mapped to roles (economic, technical, operational), and playbooks adapt per role — matching how decisions actually form.
Context vs Personalization
Personalization that focuses on identity (name, title, industry) does little to change a buying decision. Context does.
Context answers:
- what changed
- why now
- and for whom
Data tools offer identity-level enrichment. Hivekind derives context from signals, digital behavior, and role expectations.
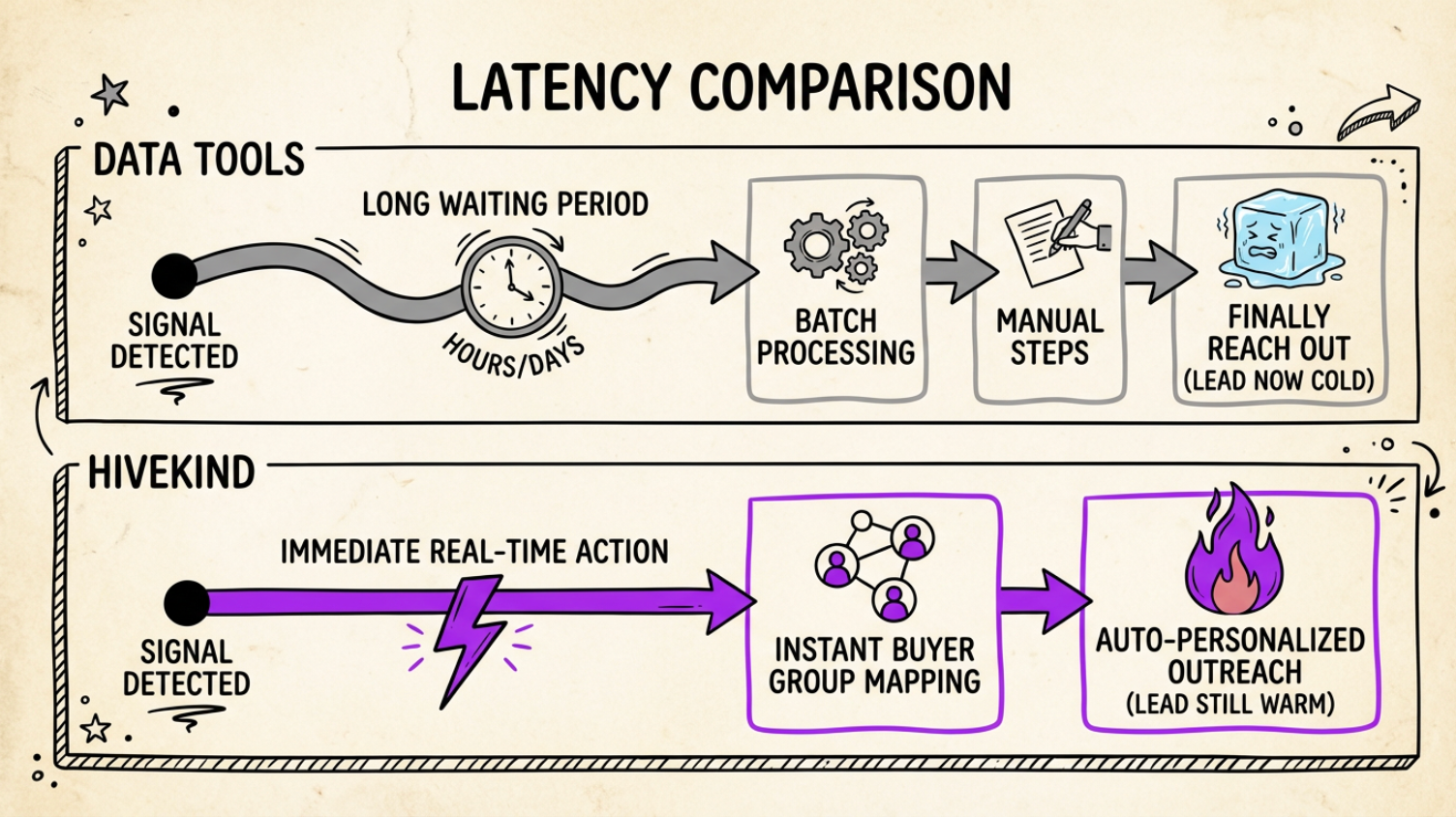
Latency: Batched Intent vs Real-Time Activation
Outbound performance now depends on time-to-action aka the interval between signal and first meaningful touch. G2 reviews rarely mention “latency” explicitly, but they describe its symptoms: backlogs of intent, unused signals, cold leads that once were warm.
Hivekind operates in real time. Signals trigger contextual interpretation, buyer-group mapping, narrative generation, and playbook execution.
Time-to-action compresses materially, and in many markets, timing is a differentiator.
Strategic Differentiation and how Hivekind trumps data tools
Hivekind’s differentiation can be summarized along three structural contrasts that correspond directly to the four gaps above.
1. Signal-to-Sequence Autonomy
Data tools stop at intent. Hivekind converts intent into activation.
- real-time signals
- buyer group identification
- contextual narrative
- sequencing and channel
- feedback-based adaptation
This closes the “real-time intent execution” gap, the most consistently cited limitation in G2 reviews.
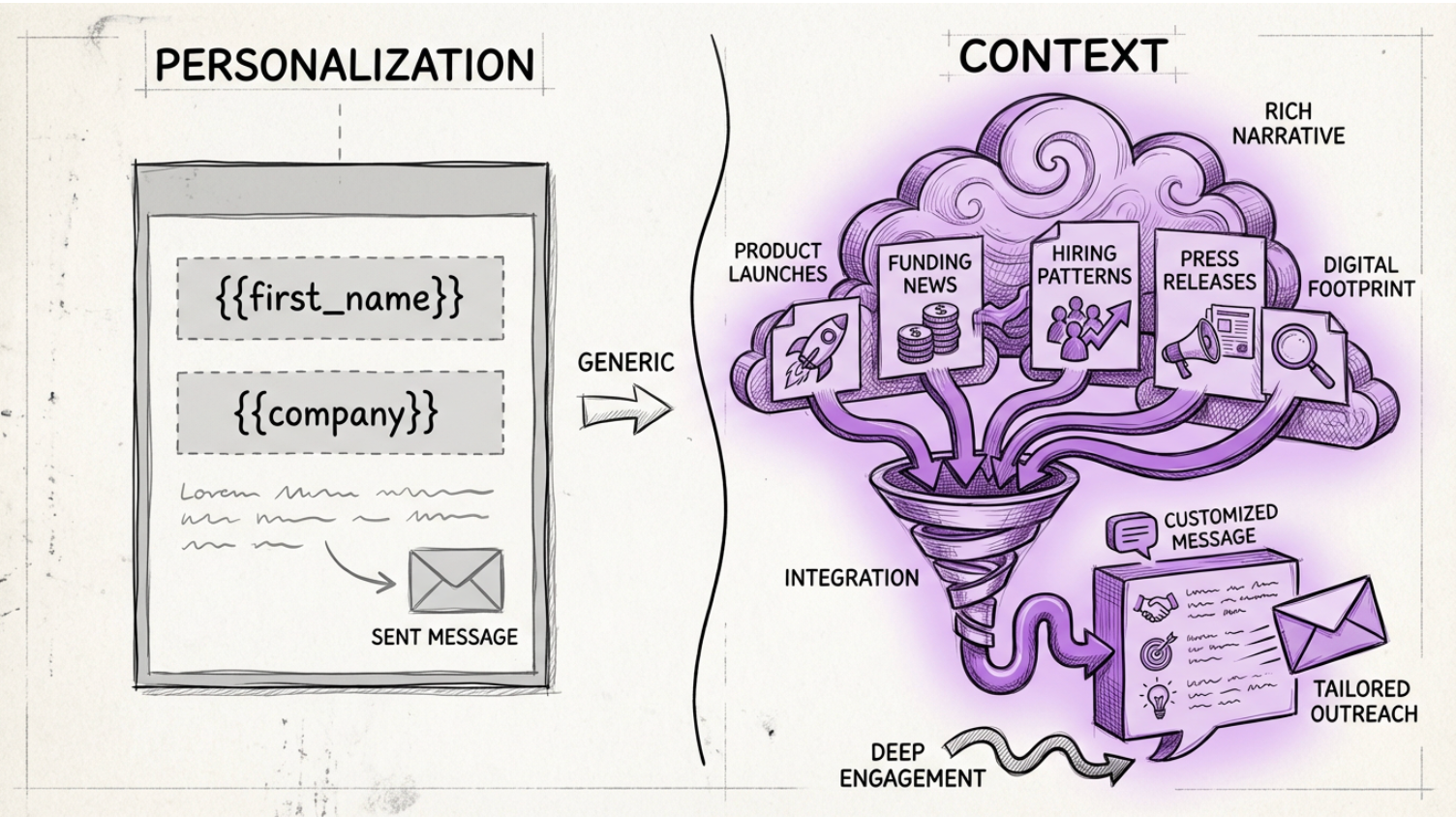
2. Hyper-Personalization at Scale
Data tools personalize identity. Hivekind personalizes narrative.
- reads digital footprint (LinkedIn, press, hiring, financial events, product updates)
- adapts messaging per role in the buyer group
- adjusts based on behavior
- prospects interactions with you to customize the next action and channel
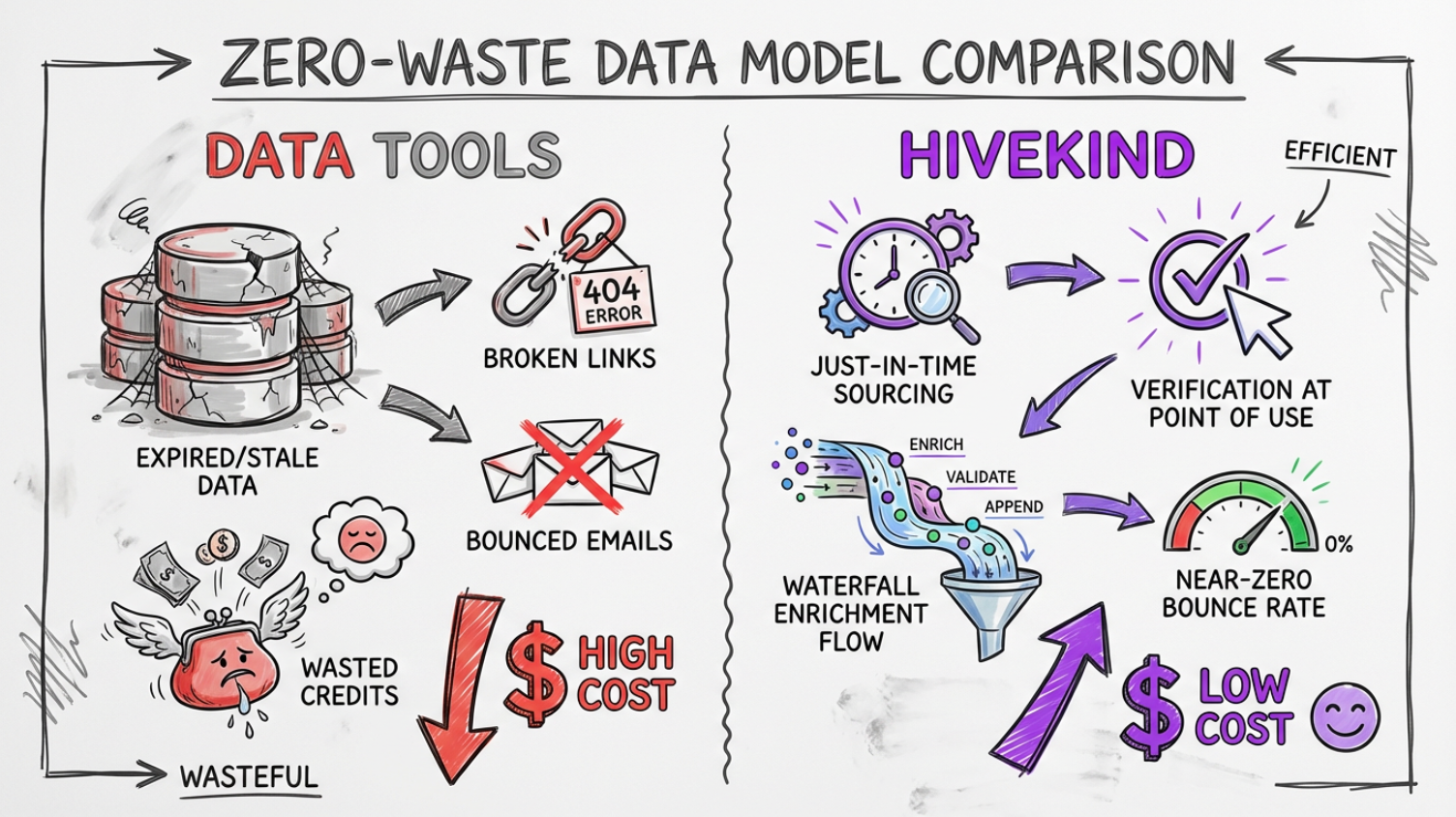
3. Zero-Waste Data Model
Data tools store data. Hivekind verifies at point of use.
- just-in-time sourcing
- deliverability pre-checks
- fuzzy verification
- near-zero bounces
- higher data coverage with waterfall enrichment (coming soon)
This addresses the “dead credits” frustration and reduces operational waste, especially painful in high-volume outbound teams.
Hivekind Vs Data Tools: The Final Verdict

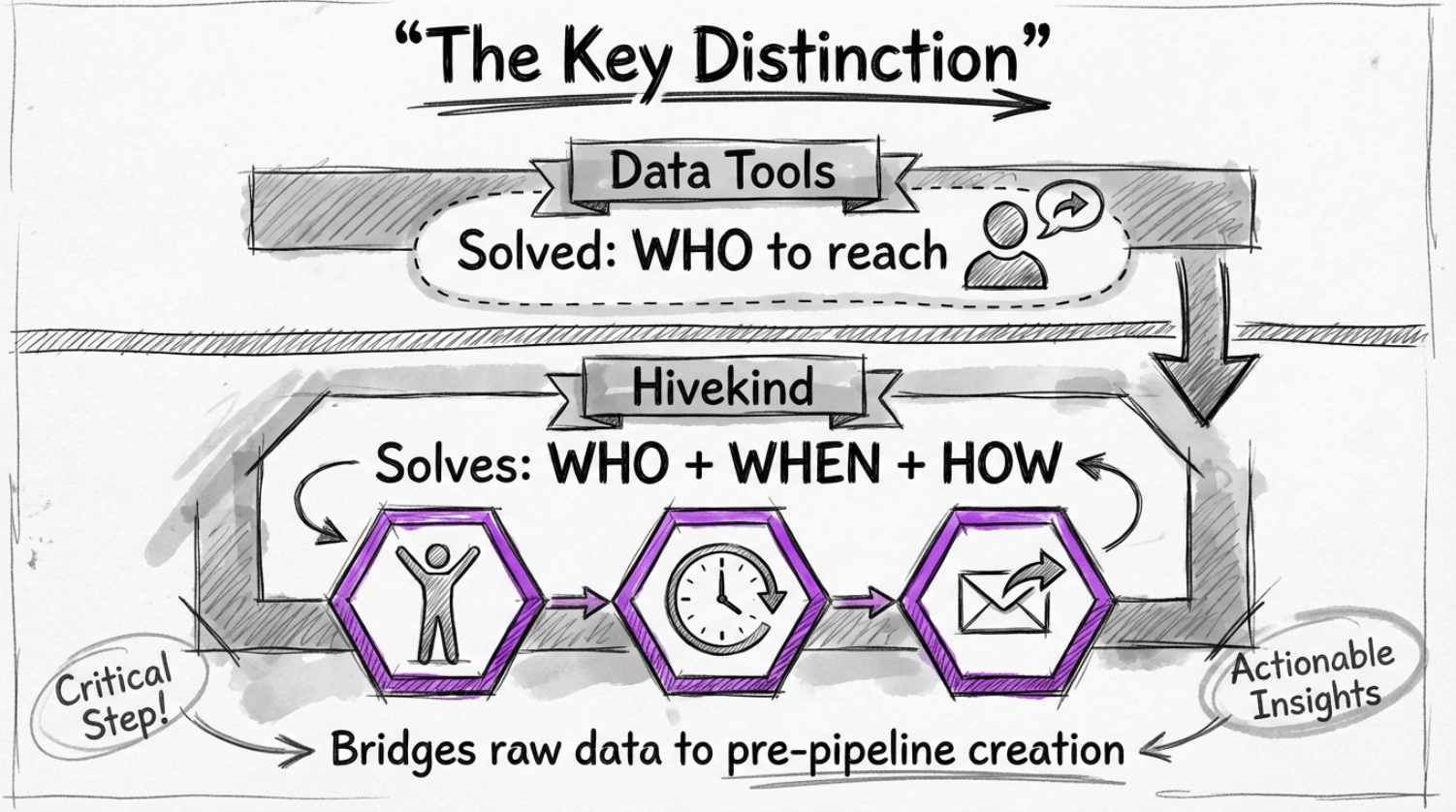
The Key Distinction
Data tools solved who to reach out to.
Hivekind solves for who, when and how, and bridges the gap between raw data and creation of pre-pipeline using the raw data.
If you are stuck with stale data and static intent and want to address pre-pipeline gaps for your B2B SaaS business, let’s talk.